(c) 1996. All Rights Reserved. This document may be freely distributed and copied provided this copyright notice is preserved.
This document defines and discusses the basic principles, assumptions and techniques employed in providing software based Fault Tolerance and High Availability in modern systems. It also surveys some of the leading commercial technologies and assesses their relative strengths and characteristics.
This document was originally written as an internal assessment of High Availability design approaches and technologies for Nortel. Such proprietary references and considerations have been omitted to make the material suitable for a more public audience. Any remaining idiosyncrasies in the presentation style or content can be attributed to this editing. In particular, a basic familiarity with the terminology of modern distributed object systems is assumed, since this was the level of readership initially addressed by the internal audience.
The survey begins with some definitions, which formally lay out terms such as system, faults, failures, Basic, High and Continuous Availability, and replication. The usage of these terms in this document is generally consistent with industry practice, but where there are discrepancies, these are pointed out.
The document then goes on to consider the policies and considerations which the builders of a software system should go through when contemplating what level of Availability is appropriate for their project, and which class of technologies is most suitable.
Finally, it concludes with a survey of some commercially available products which address some aspect of the general High Availability problem.
The terms relevant to a discussion of High Availability (HA) and Continuous Availability (CA) are now defined, to clarify the usage in later sections.
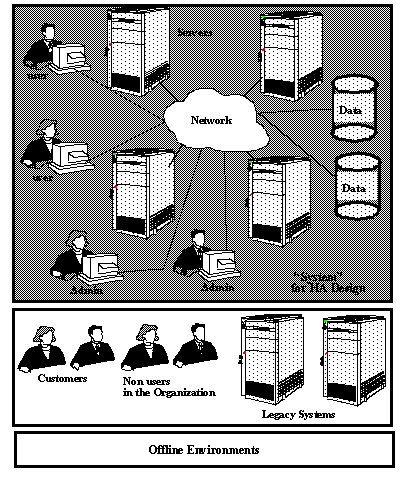
The system under discussion includes all those components and aspects of the execution environment to which the design for Availability applies. This does not mean that all of these components are necessarily made Highly Available, but only that they lie in the scope of the "system", and that the design for HA is aware of them.
The system includes the following components and aspects:
The following items are not part of the runtime system to which an Availability solution typically applies.
Based upon the definitions above, the following diagram illustrates the system with which the HA design is concerned:
A fault is a deviation from the expected behaviour of the system. In other words, if the system is specified to exhibit a certain functionality, and in the process of execution the system produces a discernibly different functionality, a fault has occurred. Functionality is typically delivered from the system by enacting a procedure to execute the logic contained in software that runs in a hardware environment (containing client and server machines, networks, data storage, and other peripherals). Faults can occur in any of the procedures, software, or hardware. Faults can be classified as reproducible (a prescribed set of actions leads to the observance of the fault in a predictable manner) or non-reproducible (the appearance of the fault is random, or is linked to a root cause outside of the environment for which the system was engineered).
Note that the literature makes a distinction between faults and failures: Faults are defined as non-compliances within the system which may or may not be externally visible to the end user, while the set of Failures contains those faults which are externally visible. This distinction is not observed in this document, and the terms Fault and Failure are used synonymously.
There are different types of faults:
There are other fault types not necessarily covered in the above categories (e.g. race conditions between software processes, data garbled in transmission over a network, etc.). There are further distinctions between benign faults and malicious (or Byzantine) faults, but a discussion of this is beyond the present scope. A basic distinction can be drawn however between reproducible and non-reproducible faults. A further distinction between "hard" reproducible faults (ones which occur identically on every run with the same inputs) versus "soft" reproducible faults (ones which may occur, with a certain probability, on identical runs). These distinctions are important in a distinction of High Availability, since HA is quite useful in dealing with "soft" reproducible and non-reproducible faults, but less effective with "hard" reproducible faults.
An outage is a deviation from the specified behaviour of the system, whether expected or unexpected. In other words, outages include all the fault categories discussed above (these are known as unplanned outages) as well as planned outages. In these latter cases, the system (or parts of it) are intentionally prevented from delivering their specified functionality in order to perform maintenance operations, software upgrades, etc.
A system which is designed, implemented and deployed with sufficient components (hardware, software and procedures) to satisfy the system's functional requirements, but no more, has Basic Availability (BA). Such a system will deliver the correct functionality so long as no faults occur and no maintenance operations, etc. are performed. Whenever a fault occurs or a maintenance operation is performed, however, an outage may be observed. Typically, Basic Availability systems are deployed as simplex (non-replicated) systems.
A system which is designed, implemented and deployed with sufficient components to satisfy the system's functional requirements but which also has sufficient redundancy in components (hardware, software and procedures) to mask certain defined faults, has High Availability (HA). This definition is ambiguous: the terms "sufficient", "mask" and "certain" require further clarification. Before doing so, however, it is emphasized that due to this ambiguity there is a continuum of configurations which can be classified "High Availability" with this definition.
The ambiguous terms are now further defined:
Continuous Availability (CA) extends the definition of High Availability, as given in the previous section, and applies it to planned outages as well. Recall that faults were identified as unplanned outages, but that the total set of outages to a system consists both of unplanned outages as well as planned outages. High Availability, as defined, compensates for unplanned outages. Continuously Available systems must have a masking strategy that deals with planned outages as well.
Implicit in the more strenuous definition is that, whereas the definition of HA permitted a variety of masking strategies (cold, warm and hot standby), a CA system is confined to being exclusively Hot Standby/Active Replication- transparent masking must be complete, not just for faults, but for planned outages as well.
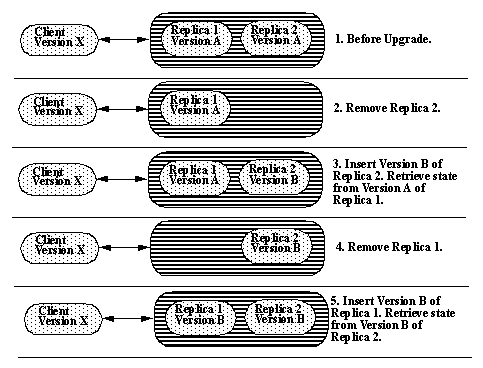
To recognize the difficulties inherent in this, consider the implications for a software upgrade. Initially, two identical processes are replicas of each other (see Figure 2, step 1.). To perform an upgrade, one replica is taken out of service, and replaced with the upgraded Version B (steps 2. and 3.). When it comes on-line, Replica 2 must absorb the processing state from its (Version A) peer. That peer is then shut down, at which time clients are left with only the Version B replica (step 4.). Finally, the fully replicated system is recreated with both replicas upgraded to Version B. Note that to achieve this, server versions A and B must be sufficiently compatible to share processing state between them. Also, clients (which typically have an independent lifecycle, represented as Version X), must be able to transparently interoperate across server versions A and B. Similar issues arise when the clients are upgraded from X to Y. All of these issues of compatibility depend upon the application state and behaviour; there are no "easy" middleware solutions to these requirements. In fact, if the upgrade from Version A to B is significant enough (e.g. a large amount of new functionality added in Version B), it may not be possible at all.
The definition of the System identified the components with which the HA design is concerned. It did not imply that all of these components are, in fact, replicated to provide High or Continuous Availability. Rather, the System must be further decomposed to identify those components which are Basic, High, or Continuous Availability, and for those that are High Availability, identify whether they are Manually Masked, Cold, Warm or Hot Standby/Active Replication. The system is thus divided into Domains of Availability. This is done for any of the following reasons:
The task of a High Availability design, then, is to:
Figure 3 demonstrates graphically this logical division. The challenges confronting a High Availability design are to determine the appropriate partitioning, and to ensure that the system as a whole is "knit together" in a meaningful fashion. That is, there is little value in making a database server Continuously Available, if the server software which accesses it is only Basic Availability.
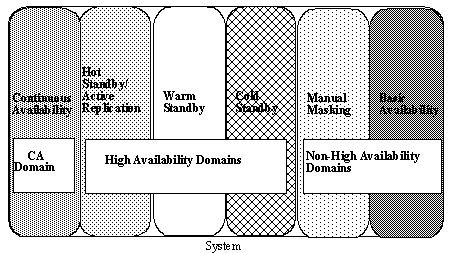
Figure 3 : The "System", as shown in Figure 1, divided into Availability domains. Increasingly more strenuous forms of availability are shown right to left.
Previously, the term Active Replication was introduced as a synonym for Hot Standby (one that better reflected the symmetric relationship between replicas). Active Replication (AR) is also used to describe the set of techniques used to achieve Hot Standby, by actively and completely sharing processing state between replicas. Since "state" is a dynamic entity in a distributed system, and changes constantly, sharing state implies not only transferring information between replicas, but also coordinating and synchronizing the information. This is needed so that replicas present their state externally, and process it internally, in a consistent manner.
In general, changes in state are non-commutative (i.e. applying two state changes {A,B} for a state transformation S -> SA -> SAB results in a different end state than {B,A} applied: S -> SB -> SBA, SAB<>SBA). Hence, "synchronizing" a system's state really means ensuring that operations are applied in the same order to all participant replicas (i.e. that all replicas are either SAB or SBA, but not a combination of both).
Active replication techniques are thus largely concerned with ordering operations. The best known Active Replication technique is the Virtual Synchrony model found in Isis, whose name is an attempt to convey this sense of enforced synchronization through ordering. The various AR techniques available (causal ordering, total ordering, etc.) are attempts to trade off more or less rigorous ordering guarantees with their respective performance overheads (in general, the more rigorous the order, the more degraded is the performance).
In addition to providing an ordered communications vehicle, AR systems need mechanisms to support the notions of "groups" of replicas, and have membership services which identify, in a distributed sense, which processes are members of a group at any time. Mechanisms are needed to allow members to join a group and "catch up" to the processing state of the group, and to be removed from a group either voluntarily or in response to a detected failure in a member. Hence, AR systems invariably include failure detection and heartbeat mechanisms as part of their group membership services.
AR is frequently associated with the notion of "Make Forward Progress" (MFP) systems, since by maintaining consistent server replicas, clients are not interrupted in the event of a failure, and are always able to advance the state of their work.
The terms Hot Standby, Active Replication,
Virtual Synchrony, and Make Forward Progress have been identified
as being largely synonymous, merely putting different emphasis
on different aspects of the same behaviour. This observation is
summarized in the following table:
Passive, or lazy, replication (LR) describes a set of techniques used to achieve Warm Standby. Recall that Warm Standby was defined as a replicated system in which some amount of initialization and state sharing occurs between replicas. In practice, Warm Standby solutions are often used as a relaxed form of "Hot Standby" High Availability, because Active Replication can be quite costly in terms of performance and application design complexity. The amount of "relaxation" from the stringent HS/AR varies, however, so that there are many approaches which can legitimately call themselves "Warm Standby", but which have widely differing amounts of initialization and state sharing (see Figure 4).
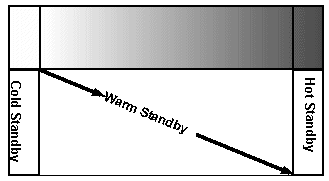
Figure 4 : A "Spectrum" of High Availability, showing that Cold & Hot Standby solutions occupy relative extremes, whereas Warm Standby covers a broad middle ground, with many approaches that can legitimately be considered "Warm" Standby.
Examples of Warm Standby approaches include:
N.B. - the above are intended as examples only - there are many other replication approaches which could qualify as "Warm Standby".
LR is frequently associated with the notion of "Rollback
& Recover" (RR) systems, since even with some state maintenance,
clients are interrupted in the event of a failure, and must explicitly
rebind to the standby. The following table summarizes the terminology
used in this section:
Load Balancing is a mechanism used to achieve scalability, by spreading the work load across a pool of servers. Hence, it technically has nothing to do with High Availability and Replication. In practice, however, the concepts are frequently linked because the investment made in purchasing redundant systems for High Availability cannot be justified if the additional equipment is idle, or is merely duplicating the work performed in the primary servers.
Rather, a frequent customer requirement is to have a pool of replicated servers which are prepared to substitute for each other in the event of a failure (their High Availability role), but which divide the client workload under normal (non-failure) conditions (their Load Balancing role). Such a requirement, while common, can significantly complicate the design of both aspects (HA and Load Balancing), since the computing configuration cannot be optimized for either role.
In addition, the functional implications of such compromise designs must be considered. If a system is tuned to support a normal client load with a load balanced pool of N servers, and subsequently suffers a failure on one server, the load must now be spread across N-1 servers. This will clearly impact overall system performance, and hence not properly "mask" the failure (since the performance degradation will be observed). Of course, the system can be over-provisioned with more than N servers, allowing a prescribed number of failures to occur before performance is affected. However, this returns to the initial point of purchasing spare capacity. In most cases, N=2, and the Load Balancing requirement is to spread the load across both. Adding a third server for over-provisioning is not an option.
An analogy may be useful here: consider a whole life insurance policy, with an accumulated positive balance. The purpose of the policy is to safeguard the holder's family in the event of death or similar catastrophe. However, the balance in the policy can be used, at its owner's discretion, to fund normal living expenses. The danger, of course, is that by using the policy's resources during life, its benefits may not be there when they are truly needed, at death.
High Availability, and the supporting technology, systems and software design, should be thought of as an insurance policy that has a net positive balance (i.e. the spare processing capacity of the redundant servers). By "borrowing" from this balance in normal non-failure operations, the benefit of the HA insurance is reduced in the event of system failure.
This trade-off must be considered by the system planners and customers.
We earlier introduced the concepts of Active Replication of state information between processes collected in "groups", which in turn possess membership services to enable processes to join or leave groups. This notion of tightly synchronized groups of processes, which exchange well-ordered messages between them, can be applied to problem domains other than High Availability. That is, group-based computing can be considered as a generic distribution paradigm, and its usage for Active Replication and High Availability is only one (important) example of this paradigm.
A great deal of research has been done on distributed models that involve groups (see [Doug Lea], [Transis work], [Isis coordinator/cohort]). One application is in the construction of compromise Load Balancing/High Availability systems, as described in the previous section. Other, more general applications, include models of cooperative computing, in which the specialized roles of "clients" and "servers" are dropped, and all distributed application components (objects) cooperate by using "divide and conquer" techniques to solve a problem. The ordered messaging of the group assists these objects to shared their partial solutions with each other, in constructing a total solution. Such a concept could potentially be applied to agents, as well. Agents are distributed software entities which are able to "roam" a network, and perform work at various locations in it. Again, the integration of the results of these agents into a coherent whole could be achieved by a totally ordered communication model.
There are many issues to consider in such models, which are still the subject of active research. For example, the tight ordering imposed by group computing also enforces a determinism by removing the natural asynchrony (and hence non-determinism) in the original non-ordered distributed system. Such deterministic systems are provably weaker in their problem-solving ability than non-deterministic ones. Hence, one of the main benefits which can be obtained by moving to a distributed model, i.e. a more powerful computational model, can be lost by imposing too much order.
A further discussion of these subjects is beyond the scope of this document.
This section is primarily intended for Product Management and Technology Planning groups, and perhaps even for customers, to convey the cost/benefit trade-off of the different Availability options. I.e., Continuous Availability and Active Replication are nice in concept, but they carry a monetary, performance and complexity cost that must be understood in the product. This is needed in order to understand the core Availability requirements that must supported in the software system, and what the costs are of supporting these requirements.
The Definitions given in the previous section attempted to give a rigorous and consistent taxonomy to terms like 'High' and 'Continuous' Availability, and to note the distinctions and relationships between the various 'temperatures' (Cold, Warm and Hot) used to modify the notion of a mated-pair configuration.
However, typically when designing a system with High Availability requirements, those requirements are expressed by customers with their own lexicon and meaning applied to the common terms. It is therefore extremely important to be able to translate from a more 'canonical' terminology, such as was offered above, to the customer's needs. Frequently, those needs are expressed simply as 'the system needs to be 24X7', as if that says it all! When pressed, this may be amended to 'No data should ever be lost, and the system should remain functional and operational at all times with no perceived loss of service. Maintenance and upgrade activities should not interfere with operational service.' A tall order, no doubt.
Without being properly informed of the total costs and consequences of getting a Rolls Royce model, it is natural to want precisely that. It is only after realizing that in addition to the higher up front sticker cost, there is an increased cost for insurance, gas mileage, spare parts and qualified servicing that a consumer is sufficiently educated to weigh the options between a deluxe and economy model more appropriately. Caveat emptor!
Just as when shopping for cars and other consumer items, investing in complex system software requires some education and critical thought. And, just as the marketing and advertising for consumer items frequently attempts to cloud the issues and present their products as being suitable to tasks they are not, similarly the High Availability marketplace is full of glossy brochures trumpeting '24X7 capability'. No wonder, then, that customers believe this is a straightforward requirement to impose on their systems.
In short, both the users of computing systems and the creators of those systems tend to be considerably more interested in specifying the functional requirements of a system: what usable capabilities does it possess. Discussions of the system's performance, scalability, reliability, etc. tend to be decidedly less glamorous. Nonetheless, these 'non-functional' requirements are no less important for the overall usefulness of the system, and imply no less (and frequently more) complexity in design than do the functional requirements.
It is ultimately the responsibility of the users of the system and its builders to work together in communicating (i) what is actually required by the users, as opposed to what they might like to have (ii) the technological alternatives that could be used to meet those needs (iii) all the costs: monetary, but also performance degradation and system complexity due to replication algorithms, group membership protocols, etc.
The following "Service Class Matrix" encapsulates the HA requirements of one such customer. As customer requirements go, this presentation shows a reasonable amount of sophistication in the subject matter on the part of its author. It is presented as an example to identify the types of considerations that the builders of a new system need to go through.
The matrix identifies 4 'quadrants' of system behaviour: Basic
Availability, High Availability, Continuous Operations and Continuous
Availability. The intent of this customer on accepting a new system
would be to identify the independent MTTF and MTTR values for
each component (hardware, software, network connection, manual
procedure, etc.) and combine them in series and parallel, as appropriate,
to identify the total MTTF/MTTR and availability for the system.
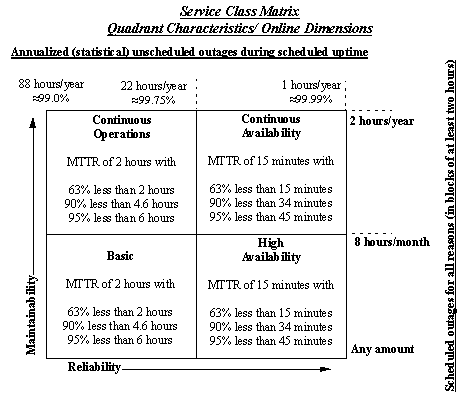
The goal of this particular company was to aggressively aim to get all of their operational business systems initially into the High Availability quadrant, and subsequently the Continuous Availability quadrant. This was a blanket statement, with no further analysis of why CA should be desired across the board. Again, with no analysis of the costs of CA, it is easy to ask for it.
Furthermore, note that the matrix defines 'Basic Availability' as having an MTTR in the range of several hours! This essentially implies that all systems are already replicated, with some form of automatic detection and recovery strategy. That is, BA on the Service Class (SC) Matrix corresponds approximately to what we defined earlier as a Cold Standby, or perhaps Manual Masking, variant of High Availability. Unlike our earlier taxonomy, the SC Matrix makes no allowance for a simple, run of the mill, unreplicated system. Since the vast majority of business systems are simplex, this is a very curious omission.
Finally, the SC Matrix makes no allowance for Domains of Availability. The entire system is expected to have one categorization. This is exceedingly inflexible in a large distributed system. For example, it is quite unreasonable to expect a desktop client used to perform a non-critical audit function to share the same availability criteria with the core data servers.
Considering that the SC Matrix is the product of a fairly enlightened approach to the subject of Availability, and that customer requirements are typically far less well communicated, what then is a design community to do when searching for a High Availability technical architecture?
Here are a number of suggestions:
In the remainder of this document, a number of commercial technologies are described, and for each, their fit to both the neutral model given earlier in this document, as well as the SC Matrix, is assessed.
This section summarizes the middleware technologies which have capabilities which may be of use in implementing a design for High Availability. Some of these products are specifically designed for High Availability. Others are tools with some other primary purpose (database, TP monitor, etc.), but which make some provision for replication and availability. The list is by no means exhaustive; rather it reflects only the technologies examined by one particular design group in the course of a specific project.
ServiceGuard is HP's primary High Availability middleware offering, available on HPUX. It allows application software to be organized into packages which are installed on server clusters (typically pairs). A package is assigned disk resources (HP Logical Volumes) and network resources (an IP address). These resources remain attached to the package, even across faults. I.e., ServiceGuard performs a heartbeat between the machines in its cluster, and in the event of a perceived failure, it can shut down a package and restart it on a healthy machine with the same network address it had previously, and with the same disk resources it had previously. It achieves the network address transparency by mapping the "floating" network addresses to the "fixed" IP addresses which remain attached to the machines.
It achieves the disk resource transparency by connecting multi-ported disks (e.g. F/W SCSI) to the participating machines in the cluster. A Distributed Lock Manager (DLM) ensures that only a single host has write access, to prevent data corruption. The activities of starting and stopping application packages, and performing any specific startup and shutdown activities required, is done in shell scripts which are written by the application developers.
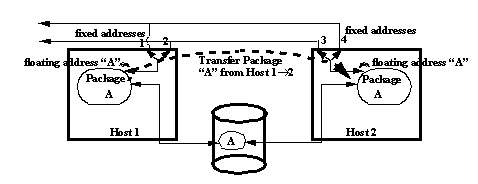
ServiceGuard is HP's offering in a field which has very similar offerings from its competitors, such as IBM HACMP, and the Openvision*HA product for Sun. All of these products are targeted at systems which want a straightforward replication mechanism on off-the-shelf UNIX equipment (unlike expensive Tandem or Stratus Fault Tolerant systems), with little or no application development. ServiceGuard and its competitors are designed to slide underneath existing applications, such as databases, transaction monitors, applications servers, etc. with no code modifications. The only development required is to create the shell scripts used to manage the start-up and shut-down operations. Clients attempting to access their servers can also remain unaware of the underlying HA middleware, and hence not require code modifications, since on failures they attempt to rebind to the same network address, which migrates to the new host of their servers. This is very useful for third party software systems for which there is no luxury of tailoring them to a "smart" HA system, and which must be installed and configured on their binary forms alone. Finally, by supporting arbitrary package definitions, and allowing packages to be configured onto all nodes in the ServiceGuard cluster, a limited form of Load Balancing can be achieved.
There are several disadvantages to the technology as a consequence of ServiceGuard's convenience and simplicity:
As has been indicated, ServiceGuard is a RR (Rollback & Recover) system. It corresponds most closely to a Cold Standby, or perhaps a primitive Warm Standby, form of High Availability, since there is only limited opportunity for state sharing occurring between replicas, and even this must be managed by the application itself, through the shell scripts and common disk storage, rather than by the middleware.
The system MTTR it would offer in a full application setting would place it squarely in the "Basic Availability" category in the Service Class Matrix.
MirrorDisk is a complementary (but independent) technology to ServiceGuard. MirrorDisk provides a device level mirroring of two physical storage devices, so that both contain identical replicas of the same logical volumes. Figure 5 identified that ServiceGuard can mask single points of failure in the processors and network connections. The disk, however, is a conspicuous single point of failure. MirrorDisk addresses this by converting the single dual ported disk into two active replicas (see Figure 6).
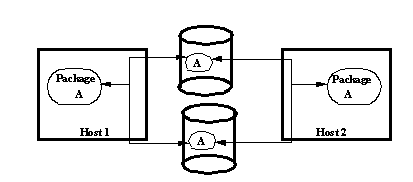
MirrorDisk can be used independently of ServiceGuard, as an online disk replication solution. Its true usefulness, however, is in combination with ServiceGuard, in order to obtain a system that has eliminated all significant single points of failure.
As with ServiceGuard, since MirrorDisk relies on hardware configurations, it is a proprietary solution available only with HP equipment. Further, it can only be used for disks in close physical proximity (same system room), and hence cannot be used for a geographical diversity system.
MirrorDisk offers an online and active form of mass-storage replication. For this specific system component, then, it can be classified as an Active Replication/Hot Standby system. For example, should a disk device fail while under the control of MirrorDisk, the applications using that disk are able to remain running uninterrupted with the remaining disk mirror, hence MTTR=0 for this type of failure.
It must be stressed, however, that AR exists only for the storage device itself. File systems, database systems, etc. which reside on top of the physical device are not actively replicated, and come under the jurisdiction of ServiceGuard, if it is being used.
Somersault is the project name for an HP Labs Bristol activity to produce a group-based, Active Replication mechanism. It is influenced strongly by Isis, and related industry efforts for Active Replication systems. However, where Isis presents a very general group computing mechanism (Virtual Synchrony), whose groups can be used for purposes other than High Availability, Somersault is targeted specifically for HA. This reduces its generality, but reduces its complexity, and presumably improves its performance. Somersault is not a product offering from HP at this time.
Somersault could be applied to distributed systems which have Hot Standby/Active Replication requirements. It supports total state replication between application replicas, if so desired, and also provides automatic client reconnection to a standby following a failure. Hence, MTTR can be reduced to zero. Furthermore, since it is network based, it does not have the proprietary dependencies on hardware that are found in ServiceGuard, and it can support replicas separated over a WAN (geographical diversity). Being communications-based, it, like Isis, has a CORBA strategy: Somersault will support an "ORB Plus + Somersault" model. It is well suited to the telecommunications management environment, offering management abilities and resource definitions that map well to the operational environment of telecommunications. Somersault is not applicable to a general cooperative group-computing paradigm. It is also not well suited to mass active replication of secondary storage (disks) (i.e. it has no equivalent to IDB- Isis for Databases).
Somersault is a middleware technology that supports HS/AR applications.
Applications built with this technology should be able to be positioned in the "High Availability" quadrant of the Service Class Matrix.
Isis, a subsidiary of Stratus Computers, offers a family of products, all devoted to supporting applications frameworks which have a requirement for HS/AR. The base product, the Isis Software Development Kit (SDK), is common to all the other product offerings (see Figure 7). The SDK itself, however, offers an extremely complex and proprietary set of APIs. Hence, it is generally not considered a viable middleware option on its own. Rather, some of the vertical Isis offerings shown in Figure 7 are typically used to ease application development.

Orbix + Isis (O+I) offers a CORBA-compliant distribution model for Actively Replicated process groups. Applications can be developed using the traditional Iona Orbix C++ bindings, and then converted to being Orbix + Isis servers. O+I has group membership services, including heartbeat detection, join and exclusion primitives. It supports total message ordering, as well as less stringent (but more efficient) causal ordering, leaving the choice up to the developer. It supports a general cooperative group computing paradigm, and while it is primarily intended for High Availability, it can be used by any applications that need a totally ordered ("Virtually synchronous") computing model. Being network based, it has no proprietary hardware dependencies. It is supported on multiple common platforms (HPUX, Solaris, IBM AIX, Windows NT), and groups can be composed of server processes running on heterogeneous combinations of these platforms. Isis groups can be distributed over Wide Area Networks, allowing for geographic diversity.
In addition to its standard Active Replication model, Orbix + Isis also supports a Coordinator/Cohort model. While this model can still fully mask failures from clients as in the Active Replica model, it does so in a "lazy" replication style, which can be considerably more efficient, depending upon the size of state to be transferred relative to the cost of computing that state from the client inputs. Coordinator/Cohort can also be a useful load balancing tool, since a group can nominate different members to be coordinators for different client operations simultaneously.
Finally, Orbix + Isis has an Event Stream model which decouples the client and server in an interaction and funnels their operations through an Event Queue. This Event Queue can optionally store messages persistently, and is itself implemented as an Actively Replicated (hence Highly Available) Isis group. This yields a CORBA based publish/subscribe mechanism, with fully ordered, guaranteed message delivery to intended recipients, whether they are executing at the time of transmission or not.
Orbix + Isis is specifically intended for CORBA based applications which are widely distributed, and mission critical. In other words, applications that due to the sheer number of components involved, will have small system MTTF values (something is failing almost all the time throughout the distributed environment), yet the system as a whole is expected to have very high availability. Hence, all important system components need to be actively replicated to mask failures to the users of the system. Unfortunately, there are several known difficulties with the technology:
Orbix + Isis is a middleware technology that supports HS/AR applications. Applications built with this technology should be able to be positioned in the "High Availability" quadrant of the Service Class Matrix.
Isis for Database (IDB) extends the Isis Active Replication paradigm by using the Isis SDK to mirror large pools of secondary storage. In this sense, its goal is similar to that of MirrorDisk. However, since it does not rely on hardware configurations and is constructed from the networked software architecture of the Isis SDK, it is portable across hardware platforms (HPUX, AIX, Solaris, etc.) and it can be extended over Wide Area Networks to provide disk replicas at geographically large distances from each other (although for this to be practical, LAN-type bandwidths would be required, e.g. 10 Mbps WAN. This would probably require a dedicated SONET ring between the geographically remote locations).
IDB supports the on-line (active) streaming of data to the mirrored databases. It does this by taking control of the "commit" verb of application transactions. This means that IDB must be specifically tailored for every target database. Versions of IDB have been provided for Oracle and Sybase at this time. A database failure, or the failure of the underlying storage mechanism, is masked completely, meaning that applications using IDB can continue transactions in progress unimpeded to the remaining replica(s). When the failed volume is returned to service, state (the delta of all missed transactions) is spooled from an active member of the Isis group to the newcomer in the background, until it is resynchronized. Application transactions continue unimpeded while this Data Synchronization occurs.
IDB is useful in systems that require Active Replication of large, persistent databases, especially when this requirement is to be met in a portable (multiple database types, multiple hardware platforms) setting, and potentially where the replication can span geographically diverse sites.
Shortcoming with IDB include:
IDB/O+I integration Since IDB is a vertical Isis application directly employing the Isis SDK, it is not integrated to O+I. In fact, its APIs are purely procedural, and support no object notions at all.
Database Versions. A version of IDB would be required for every database type that is to be replicated, since IDB actively takes control of the transactional sequence. (In this sense, IDB acts very much like a transaction monitor).
Third Party Data Access Support. IDB assumes that applications accessing the underlying replicated databases through it make direct embedded SQL or CLI (Call Level Interface) invocations, so that it can take control of the commit verbs. In cases where a third party tool is used to generate the low level data access (e.g. Persistence, Odapter, etc.), the tool would have to be modified by its vendor to support IDB's requirements that it give up control over the commit.
IDB is a middleware technology that supports HS/AR for persistent storage components (i.e. databases and their underlying disk storage).Applications built with this technology should be able to be positioned in the "High Availability" quadrant of the Service Class Matrix.
Oracle Parallel Server (OPS) is a technology created by Oracle in partnership with each of the major hardware platform vendors on which Oracle databases run (e.g. Pyramid, IBM, HP, Sun, etc.). OPS takes advantage of the Distributed Lock Manager and multiported disk configurations discussed previously in the context of ServiceGuard, and of similar hardware and OS extensions on the non-HP platforms. OPS uses these tools to create an Actively Replicated shared state between two Oracle database managers running on clustered machines. Hence, in the event of a failure, applications which transfer to the standby instance of Oracle are able to connect almost immediately. While they are still explicitly disconnected from their original database, and any uncommitted transactions are lost and must be re-entered, committed transactions are visible almost immediately.
Hence, OPS in combination with ServiceGuard and MirrorDisk can yield a much faster database recovery, and consequently a much lower overall system MTTR.
OPS is applicable in environments that are using Oracle as the primary database server underlying their applications, and which need an improved recovery time over the pure Cold Standby model of ServiceGuard. The model is still RR (Rollback and Restart), but the recovery time is dramatically improved, and there is presumably less transactional work to be rolled back (and hence fewer dissatisfied customers).
The solution is very hardware specific, and takes advantage of DLM and multiported disk technology. It is not extensible to geographic diversity requirements.
OPS is positioned at the high end of the Warm Standby scale, approaching Hot Standby. It has nearly complete state replication between the Oracle replicas, but it still requires applications to follow a Rollback & Restart path on failure.
Applications built using OPS would lie near the boundary between "Basic Availability" and "High Availability" quadrants in the Service Class Matrix. The determination of whether an overall system was BA or HA would depend upon other application recovery criteria.
Oracle, like most database vendors today, offers a "lazy" replication model in which transactions are logged to a file, as well as being applied directly to the database. Periodically (e.g. hourly, nightly, etc.) these transaction logs are spooled to a standby server for application to a redundant database. This technique is often used for functional replication (e.g. in order to have multiple data sources physically close to their points of consumption), as well as for failure masking.
As a High Availability strategy, it offers relative simplicity, no hardware dependence, and geographical diversity (since the replication is network-based, and not dependent on multiported disks). There is a window (sized according to the frequency of the spooling of the transaction logs) in which transactions committed on the primary will not be seen on the standby, and will have to be "rolled back" in the client's (and user's) context. Furthermore, when the original primary is reintroduced back into the system, those "missing" transactions can suddenly reappear. Normalizing the divergent database views can be difficult, and invariably requires DBA (human) intervention. Hence, relying on lazy database replication is not a satisfactory "fully-automated" version of HA.
"Lazy" database replication is suitable for systems that require a relaxed form of High Availability for their persistent storage, but which can tolerate substantial MTTRs and can afford to lose the portion of their committed transactions that had not been propagated to the standby system prior to failure. While this might be thought not to apply to most mission critical business systems, because of performance, cost and technology reasons, "Lazy" replication is actually quite common in such systems today.
"Lazy" database replication is a Warm Standby approach for obtaining High Availability persistent storage replicas. The degree of "Warmth" in the Warm Standby approach is a function of the frequency at which the transaction logs are spooled, since they reflect the state sharing which is occurring. That is, replication hourly is "warmer" than replication nightly.
A system built using Lazy database replication would be located in the Basic quadrant of the Service Class Matrix.
Encina is a DCE based Transaction Processing monitor. TP Monitors are used to coordinate and synchronize ACID transactions enqueued by multiple clients against multiple resource managers (databases) in a distributed environment. Encina is not intended to be "High Availability" middleware; it is transactional middleware. However, the reliability concepts behind ACID (Atomicity, Consistency, Isolation, Durability) transactions and the reliability implied by HA are closely related.
Encina (or any TP monitor) can be used to ensure that application transactions, once entered into the system, and once committed, will reliably and durably be conveyed to a replicated set of databases, via two phase commits (2PC). However, 2PCs are computationally expensive operations, and for performance reasons, this is rarely done. In practice, Encina uses transaction logging techniques similar to those discussed in the previous section, and implements a kind of Lazy Replication. The advantage is that the log is not stored with the primary database, and so all committed transactions are seen at the replica. I.e., using the TP monitor avoids the "window" of temporarily lost transactions discussed above.
Using a TP monitor to enforce Active Replication (using 2PCs) or Lazy Replication (using transaction logs) is a reasonable approach only if the application domain is using a TP monitor already for its functional properties (i.e. distributing ACID transactions across multiple resource managers). TP Monitors (Encina, Tuxedo, CICS) are "heavyweight" pieces of middleware - they are very expensive, complex, and have large learning curves. They are rarely, if ever, introduced solely to provide HA.
If Encina (or similar TP Monitor) is used to replicate all transactions using 2PCs to identical database replicas, it can achieve a Hot Standby/Active Replication environment for its applications. (This is very similar to what IDB does, only IDB's "rendezvous" algorithm has much better performance than 2PCs, making it a practical alternative for large database replication). In this usage, a system could be positioned in the High Availability quadrant of the Service Class Matrix.
If the TP monitor is used to perform Lazy
Replication, it presents a form of Warm Standby, with a degree
of state sharing across replicas. In this configuration, a system
would be positioned in the Basic Availability quadrant of the
Service Class Matrix.
ODI (Object Design Inc.) Objectstore is an Object Oriented Database (OODB). Objectstore has a passive, lazy replication mechanism similar to the one discussed for Oracle. ODI has had discussions with Isis, and the two companies have concluded that it is possible to create an IDB version that would control Objectstore transactions. Hence, it would be feasible to have Actively Replicated Objectstore images using IDB. The companies are waiting for customer funding before proceeding with such an integration effort.
The other leading OODBs (such as Versant and Objectivity) have similar replication mechanisms.
See Oracle Domain of Applicability